
In today’s digital landscape, data has become the lifeblood of modern applications. From social media platforms processing billions of interactions to financial systems handling millions of transactions, the ability to design robust, scalable, and reliable data-intensive applications has become a critical skill for software engineers. This article explores the fundamental principles, architectural patterns, and practical considerations for building systems that can handle massive data workloads while maintaining performance, consistency, and reliability.
Core Principles of Data-Intensive Applications
The Three Pillars: Reliability, Scalability, and Maintainability
Reliability ensures your system continues to work correctly even when things go wrong. This encompasses fault tolerance, error handling, and graceful degradation. A reliable data-intensive application must handle hardware failures, software bugs, and human errors without losing data or becoming unavailable.
Scalability is the ability to handle increased load gracefully. This includes both data volume scaling and traffic scaling. As your application grows, it should maintain performance characteristics without requiring complete architectural rewrites.
Maintainability focuses on the ease with which engineers can understand, modify, and extend the system over time. This includes operability (easy to operate), simplicity (avoiding unnecessary complexity), and evolvability (adapting to changing requirements).
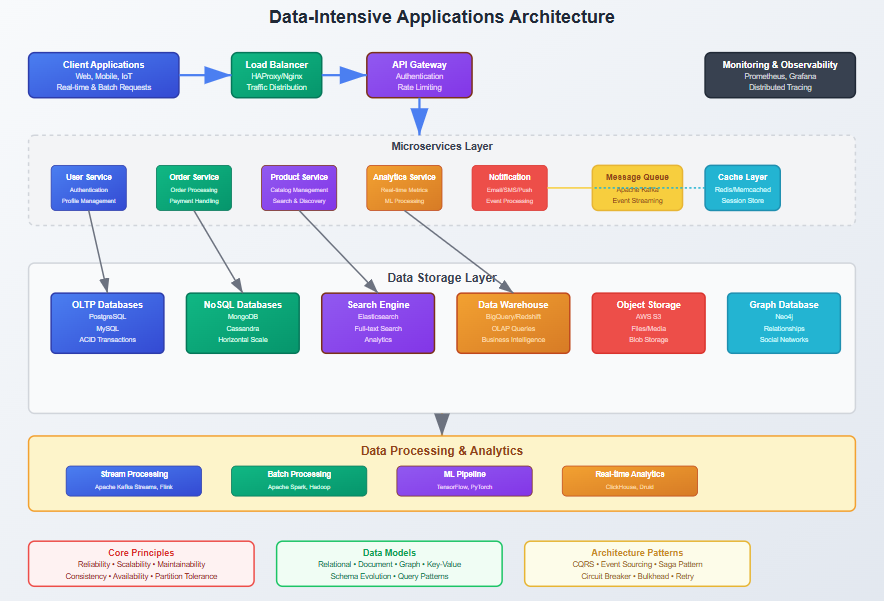
Data Models and Query Languages
Relational vs. Document vs. Graph Models
The choice of data model profoundly impacts how you think about your application’s architecture. Each model serves different use cases and comes with distinct trade-offs.
Relational Model: Best for applications with well-defined schemas and complex relationships requiring ACID transactions. Consider PostgreSQL for financial applications where consistency is paramount:
-- Complex financial transaction with strong consistency
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 1000 WHERE account_id = 'A123';
UPDATE accounts SET balance = balance + 1000 WHERE account_id = 'B456';
INSERT INTO transactions (from_account, to_account, amount, timestamp)
VALUES ('A123', 'B456', 1000, NOW());
COMMIT;
Document Model: Excels in scenarios with varying schemas and hierarchical data structures. MongoDB works well for content management systems or user profiles:
// User profile with nested preferences and dynamic fields
{
"_id": "user_12345",
"name": "Jane Doe",
"email": "jane@example.com",
"preferences": {
"notifications": {
"email": true,
"push": false,
"sms": true
},
"privacy": {
"profile_visibility": "friends",
"location_sharing": false
}
},
"metadata": {
"last_login": "2024-01-15T10:30:00Z",
"device_info": {
"platform": "iOS",
"version": "17.2"
}
}
}
Graph Model: Optimal for applications with complex relationships and traversal patterns. Neo4j is ideal for recommendation engines or fraud detection:
// Finding potential fraudulent patterns in financial networks
MATCH (a:Account)-[:TRANSFERRED_TO]->(b:Account)-[:TRANSFERRED_TO]->(c:Account)
WHERE a.created_date > date() - duration({days: 30})
AND c = a
AND length((a)-[:TRANSFERRED_TO*..5]-(c)) > 2
RETURN a.account_id, collect(b.account_id) as intermediary_accounts
Polyglot Persistence Strategy
Modern applications often benefit from using multiple data storage technologies, each optimized for specific use cases within the same system. A typical e-commerce platform might use:
- PostgreSQL for order processing and financial data (ACID compliance)
- Redis for session management and caching (sub-millisecond access)
- Elasticsearch for product search and analytics (full-text search)
- Neo4j for recommendation algorithms (graph traversals)
- S3 for image and asset storage (object storage)
Storage and Retrieval Patterns
Log-Structured Storage
Log-structured storage systems append data to files rather than updating in place. This approach offers excellent write performance and simplifies crash recovery. LSM-trees (Log-Structured Merge-trees) are the foundation of systems like Cassandra, RocksDB, and LevelDB.
# Conceptual LSM-tree write operation
class LSMTree:
def __init__(self):
self.memtable = {}
self.sstables = []
def put(self, key, value):
# Write to in-memory table first
self.memtable[key] = value
# Flush to disk when memtable reaches threshold
if len(self.memtable) > FLUSH_THRESHOLD:
self.flush_memtable()
def flush_memtable(self):
# Sort and write to disk
sorted_entries = sorted(self.memtable.items())
sstable = SSTable(sorted_entries)
self.sstables.append(sstable)
self.memtable.clear()
# Background compaction process
self.schedule_compaction()
B-Tree Storage
B-trees organize data in sorted order and maintain balance through split and merge operations. They provide consistent O(log n) performance for reads and writes, making them suitable for range queries and maintaining sorted order.
Columnar Storage
For analytical workloads, columnar storage formats like Parquet provide significant compression and query performance benefits:
# Analytical query performance comparison
# Row-oriented: Must read entire rows even for single column
SELECT AVG(price) FROM products WHERE category = 'electronics';
# Columnar: Only reads price and category columns
# Typical performance improvement: 10-100x for analytical queries
Encoding and Schema Evolution
Forward and Backward Compatibility
Schema evolution is critical for long-running applications. Consider how Protocol Buffers handle versioning:
// Version 1
message User {
required string name = 1;
required string email = 2;
}
// Version 2 - Adding optional field maintains compatibility
message User {
required string name = 1;
required string email = 2;
optional string phone = 3; // New field
}
// Version 3 - Field removal requires careful handling
message User {
required string name = 1;
required string email = 2;
optional string phone = 3;
// removed: required int32 age = 4; // Don't reuse field numbers
optional string timezone = 5;
}
Distributed Data Architecture
Replication Strategies
Single-Leader Replication: Simple to understand and implement, provides strong consistency for writes. However, it creates a single point of failure and limits write scalability.
# Single-leader replication implementation concept
class SingleLeaderReplication:
def __init__(self, leader, followers):
self.leader = leader
self.followers = followers
def write(self, key, value):
# All writes go through leader
success = self.leader.write(key, value)
if success:
# Asynchronously replicate to followers
for follower in self.followers:
self.replicate_async(follower, key, value)
return success
def read(self, key):
# Can read from any replica (eventual consistency)
return self.leader.read(key)
Multi-Leader Replication: Enables writes from multiple locations but introduces conflict resolution complexity. Useful for geographically distributed applications:
# Conflict resolution in multi-leader setup
class ConflictResolver:
def resolve_write_conflict(self, conflicts):
# Last-write-wins (using timestamp)
return max(conflicts, key=lambda c: c.timestamp)
def resolve_semantic_conflict(self, field_conflicts):
# Application-specific logic
if field_conflicts['field'] == 'balance':
# For financial data, require manual resolution
raise ConflictRequiresManualResolution()
else:
# Use vector clocks for ordering
return self.resolve_with_vector_clock(field_conflicts)
Leaderless Replication: Systems like Cassandra and DynamoDB use quorum-based approaches for high availability:
# Quorum read/write implementation
class QuorumSystem:
def __init__(self, nodes, replication_factor=3):
self.nodes = nodes
self.rf = replication_factor
self.read_quorum = (self.rf // 2) + 1
self.write_quorum = (self.rf // 2) + 1
def write(self, key, value):
target_nodes = self.consistent_hash(key, self.rf)
successful_writes = 0
for node in target_nodes:
if node.write(key, value):
successful_writes += 1
return successful_writes >= self.write_quorum
Partitioning Strategies
Key-Range Partitioning: Distributes data based on sorted key ranges. Simple to implement but can create hotspots:
# Key-range partitioning example
class KeyRangePartitioner:
def __init__(self, partitions):
# partitions = [(start_key, end_key, node), ...]
self.partitions = sorted(partitions)
def get_partition(self, key):
for start, end, node in self.partitions:
if start <= key < end:
return node
return self.partitions[-1][2] # Default to last partition
Hash Partitioning: Uses consistent hashing to distribute data evenly but loses range query capabilities:
# Consistent hashing implementation
class ConsistentHash:
def __init__(self, nodes, virtual_nodes=150):
self.virtual_nodes = virtual_nodes
self.ring = {}
self.sorted_keys = []
for node in nodes:
self.add_node(node)
def add_node(self, node):
for i in range(self.virtual_nodes):
key = self.hash(f"{node}:{i}")
self.ring[key] = node
self.sorted_keys = sorted(self.ring.keys())
def get_node(self, key):
if not self.ring:
return None
hash_key = self.hash(key)
# Find first node clockwise from hash
for ring_key in self.sorted_keys:
if hash_key <= ring_key:
return self.ring[ring_key]
return self.ring[self.sorted_keys[0]] # Wrap around
Transactions and Consistency
ACID Properties Implementation
Understanding how databases implement ACID properties is crucial for designing reliable applications:
Atomicity: Implemented through write-ahead logging (WAL) and rollback mechanisms:
-- PostgreSQL WAL example
-- Before: WAL entry created
-- Execute: UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- After: WAL entry marked as committed
-- Recovery: Replay WAL entries for uncommitted transactions
Consistency: Enforced through constraints and application logic:
# Application-level consistency checks
class TransferService:
def transfer_funds(self, from_account, to_account, amount):
with self.db.transaction():
# Check business rules
if self.get_balance(from_account) < amount:
raise InsufficientFundsError()
if amount <= 0:
raise InvalidAmountError()
# Perform transfer
self.debit(from_account, amount)
self.credit(to_account, amount)
# Verify consistency
assert self.get_balance(from_account) >= 0
Isolation: Different isolation levels provide trade-offs between consistency and performance:
-- Serializable isolation (strongest)
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SELECT balance FROM accounts WHERE id = 1;
-- If concurrent transaction modifies this row,
-- this transaction will be aborted
-- Read Committed isolation (most common)
BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT balance FROM accounts WHERE id = 1;
-- Sees committed changes from other transactions
Distributed Transactions
Two-phase commit (2PC) provides strong consistency across distributed systems but impacts availability:
class TwoPhaseCommitCoordinator:
def __init__(self, participants):
self.participants = participants
def commit_transaction(self, transaction):
# Phase 1: Prepare
prepare_votes = []
for participant in self.participants:
vote = participant.prepare(transaction)
prepare_votes.append(vote)
# Phase 2: Commit or Abort
if all(vote == "YES" for vote in prepare_votes):
for participant in self.participants:
participant.commit(transaction)
return "COMMITTED"
else:
for participant in self.participants:
participant.abort(transaction)
return "ABORTED"
Batch Processing Systems
MapReduce Paradigm
MapReduce enables processing of large datasets across distributed clusters:
# Word count example in MapReduce
def map_function(document):
words = document.split()
for word in words:
emit(word, 1)
def reduce_function(word, counts):
return (word, sum(counts))
# Distributed execution
# Map phase: Process documents in parallel
# Shuffle phase: Group by key (word)
# Reduce phase: Sum counts for each word
Modern Batch Processing
Apache Spark provides more flexible and performant batch processing:
# Spark DataFrame API example
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("UserAnalytics").getOrCreate()
# Load data
users = spark.read.parquet("s3://data/users/")
events = spark.read.parquet("s3://data/events/")
# Complex analytical query
result = users.join(events, "user_id") \
.filter(events.event_type == "purchase") \
.groupBy("country", "age_group") \
.agg(
sum("purchase_amount").alias("total_revenue"),
count("*").alias("transaction_count"),
avg("purchase_amount").alias("avg_purchase")
) \
.orderBy(desc("total_revenue"))
result.write.parquet("s3://results/revenue_by_demographics/")
Stream Processing
Event-Driven Architecture
Stream processing enables real-time data processing and reaction to events:
# Apache Kafka consumer for stream processing
from kafka import KafkaConsumer
import json
class RealTimeAnalytics:
def __init__(self):
self.consumer = KafkaConsumer(
'user_events',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
self.window_state = {}
def process_events(self):
for message in self.consumer:
event = message.value
self.update_metrics(event)
self.check_alerts(event)
def update_metrics(self, event):
# Sliding window aggregation
window_key = self.get_window_key(event['timestamp'])
if window_key not in self.window_state:
self.window_state[window_key] = {'count': 0, 'revenue': 0}
self.window_state[window_key]['count'] += 1
if event['type'] == 'purchase':
self.window_state[window_key]['revenue'] += event['amount']
def check_alerts(self, event):
# Real-time fraud detection
if event['type'] == 'purchase' and event['amount'] > 10000:
if self.is_suspicious_pattern(event):
self.send_alert(event)
Stream Processing Patterns
Event Sourcing: Store all changes as a sequence of events:
class EventStore:
def __init__(self):
self.events = []
def append_event(self, stream_id, event):
event_with_metadata = {
'stream_id': stream_id,
'event_type': event['type'],
'data': event['data'],
'timestamp': datetime.now(),
'version': self.get_next_version(stream_id)
}
self.events.append(event_with_metadata)
def get_events(self, stream_id, from_version=0):
return [e for e in self.events
if e['stream_id'] == stream_id
and e['version'] >= from_version]
def replay_state(self, stream_id):
events = self.get_events(stream_id)
state = {}
for event in events:
state = self.apply_event(state, event)
return state
Performance Optimization Strategies
Caching Patterns
Cache-Aside Pattern:
class CacheAsideRepository:
def __init__(self, cache, database):
self.cache = cache
self.database = database
def get_user(self, user_id):
# Try cache first
user = self.cache.get(f"user:{user_id}")
if user is None:
# Cache miss - load from database
user = self.database.get_user(user_id)
if user:
self.cache.set(f"user:{user_id}", user, ttl=3600)
return user
def update_user(self, user_id, data):
# Update database
self.database.update_user(user_id, data)
# Invalidate cache
self.cache.delete(f"user:{user_id}")
Write-Through Cache:
class WriteThroughCache:
def update_user(self, user_id, data):
# Write to database first
self.database.update_user(user_id, data)
# Update cache
updated_user = self.database.get_user(user_id)
self.cache.set(f"user:{user_id}", updated_user, ttl=3600)
Database Optimization
Connection Pooling:
from sqlalchemy import create_engine
from sqlalchemy.pool import QueuePool
# Configure connection pool
engine = create_engine(
'postgresql://user:pass@host:5432/db',
poolclass=QueuePool,
pool_size=20, # Number of connections to maintain
max_overflow=30, # Additional connections when pool exhausted
pool_recycle=3600, # Recycle connections after 1 hour
pool_pre_ping=True # Validate connections before use
)
Query Optimization:
-- Index optimization
CREATE INDEX CONCURRENTLY idx_orders_customer_date
ON orders(customer_id, order_date DESC);
-- Partial index for specific use cases
CREATE INDEX idx_active_users ON users(last_login)
WHERE status = 'active';
-- Query with proper index usage
SELECT * FROM orders
WHERE customer_id = 12345
AND order_date >= '2024-01-01'
ORDER BY order_date DESC
LIMIT 50;
Monitoring and Observability
The Three Pillars of Observability
Metrics: Quantitative measurements of system behavior:
from prometheus_client import Counter, Histogram, Gauge
# Define metrics
request_count = Counter('http_requests_total', 'Total HTTP requests', ['method', 'endpoint'])
request_duration = Histogram('http_request_duration_seconds', 'HTTP request duration')
active_connections = Gauge('db_connections_active', 'Active database connections')
# Instrument code
@request_duration.time()
def handle_request(request):
request_count.labels(method=request.method, endpoint=request.path).inc()
# Process request
return response
Logging: Contextual information about system events:
import structlog
logger = structlog.get_logger()
def process_payment(user_id, amount, payment_method):
logger.info(
"payment_processing_started",
user_id=user_id,
amount=amount,
payment_method=payment_method,
trace_id=get_trace_id()
)
try:
result = payment_service.process(user_id, amount, payment_method)
logger.info(
"payment_processing_completed",
user_id=user_id,
payment_id=result.payment_id,
status=result.status
)
except PaymentError as e:
logger.error(
"payment_processing_failed",
user_id=user_id,
error=str(e),
error_code=e.code
)
raise
Tracing: Understanding request flow through distributed systems:
from opentelemetry import trace
tracer = trace.get_tracer(__name__)
def get_user_orders(user_id):
with tracer.start_as_current_span("get_user_orders") as span:
span.set_attribute("user_id", user_id)
# Database call
with tracer.start_as_current_span("db_query_orders"):
orders = db.query("SELECT * FROM orders WHERE user_id = ?", user_id)
# Enrich with additional data
with tracer.start_as_current_span("enrich_order_data"):
for order in orders:
order['items'] = get_order_items(order['id'])
return orders
Security Considerations
Data Protection
Encryption at Rest:
from cryptography.fernet import Fernet
class EncryptedStorage:
def __init__(self, key):
self.cipher = Fernet(key)
def store_sensitive_data(self, user_id, data):
encrypted_data = self.cipher.encrypt(json.dumps(data).encode())
self.database.store(f"user_data:{user_id}", encrypted_data)
def retrieve_sensitive_data(self, user_id):
encrypted_data = self.database.get(f"user_data:{user_id}")
decrypted_data = self.cipher.decrypt(encrypted_data)
return json.loads(decrypted_data.decode())
Access Control:
class RoleBasedAccessControl:
def __init__(self):
self.permissions = {
'admin': ['read', 'write', 'delete', 'admin'],
'editor': ['read', 'write'],
'viewer': ['read']
}
def check_permission(self, user_role, required_permission):
return required_permission in self.permissions.get(user_role, [])
def authorize(self, required_permission):
def decorator(func):
def wrapper(*args, **kwargs):
user_role = get_current_user_role()
if not self.check_permission(user_role, required_permission):
raise UnauthorizedError()
return func(*args, **kwargs)
return wrapper
return decorator
Testing Strategies
Integration Testing for Data Systems
import pytest
from testcontainers import PostgreSQLContainer
@pytest.fixture
def database():
with PostgreSQLContainer("postgres:13") as postgres:
db_url = postgres.get_connection_url()
# Run migrations
run_migrations(db_url)
yield create_database_connection(db_url)
def test_user_service_integration(database):
user_service = UserService(database)
# Test data creation
user_id = user_service.create_user("test@example.com", "John Doe")
assert user_id is not None
# Test data retrieval
user = user_service.get_user(user_id)
assert user['email'] == "test@example.com"
assert user['name'] == "John Doe"
# Test data updates
user_service.update_user(user_id, {"name": "Jane Doe"})
updated_user = user_service.get_user(user_id)
assert updated_user['name'] == "Jane Doe"
Load Testing
from locust import HttpUser, task, between
class UserBehavior(HttpUser):
wait_time = between(1, 3)
def on_start(self):
# Login
response = self.client.post("/api/auth/login", json={
"username": "testuser",
"password": "testpass"
})
self.token = response.json()['token']
self.headers = {'Authorization': f'Bearer {self.token}'}
@task(3)
def view_products(self):
self.client.get("/api/products", headers=self.headers)
@task(1)
def purchase_product(self):
product_id = random.choice([1, 2, 3, 4, 5])
self.client.post(f"/api/products/{product_id}/purchase",
headers=self.headers,
json={"quantity": 1})
Conclusion
Designing data-intensive applications requires a deep understanding of distributed systems principles, data modeling techniques, and performance optimization strategies. The key is to make informed trade-offs based on your specific requirements for consistency, availability, partition tolerance, and performance.
As you architect these systems, remember that complexity should be introduced incrementally. Start with simple, proven solutions and evolve your architecture as your understanding of the problem domain and scale requirements become clearer. The patterns and principles discussed in this article provide a foundation for building robust, scalable data-intensive applications that can evolve with your business needs.
The landscape of data-intensive applications continues to evolve rapidly, with new technologies and patterns emerging regularly. Stay curious, experiment with new approaches, and always measure the impact of your architectural decisions on both system performance and developer productivity.







